Abstract

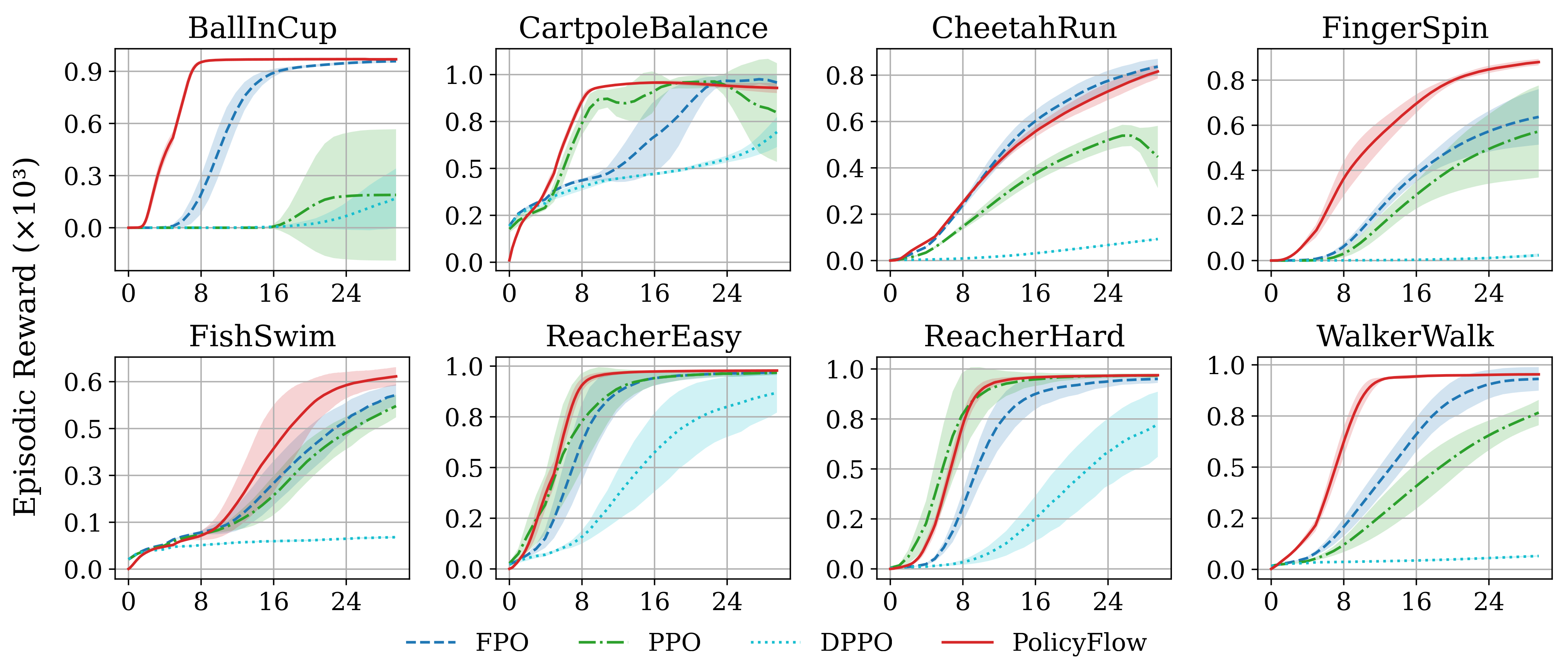
Among various on-policy reinforcement learning algorithms, Proximal Policy Optimization (PPO) demonstrates its unparalleled simplicity, numerical stability, and empirical performance. It optimizes policies via surrogate objectives based on importance ratios, which require nontrivial likelihood evaluation. Although the Gaussian policy assumption simplifies the likelihood evaluation step, it could potentially restrain the performance of the resulting policy. Replacing Gaussian policies with continuous normalizing flows (CNFs) represented via ordinary differential equations (ODEs) enhances expressiveness for multi-modal actions but inevitably leading to much more challenging importance ratio evaluation. Conventional likelihoods computation with CNFs is typically conducted along full-flow paths, which demands costly simulation and back-propagation and is prone to exploding or vanishing gradients. To resolve this issue, we propose a novel on-policy CNF-based reinforcement learning algorithm, named PolicyFlow, which integrates expressive policies with PPO-style objectives while avoiding likelihood evaluation along the full flow path. PolicyFlow approximates importance ratios using velocity field variations along a simple interpolation path, reducing computational overhead while preserving the stability of proximal updates. To avoid potential mode collapse and further encourage diverse behaviors, PolicyFlow introduces an implicit entropy regularizer, inspired by Brownian motion, which is both conceptually elegant and computationally lightweight. Experiments on diverse tasks in vairous environments such as MultiGoal, IsaacLab, and MuJoCo Playground show that PolicyFlow achieves competitive or superior performance compared to PPO with Gaussian policies and state-of-the-art flow-based method, with MultiGoal in particular demonstrating PolicyFlow’s ability to capture diverse multimodal action distributions.